HRVQA
High-Resolution aerial image Visual Question Answering
Visual question answering (VQA) is an important and challenging multimodal task in computer vision. We bring VQA task to high-resolution aerial images and propose a large-scale dataset HRVQA based on a semi-automatically construction scheme, which covers the inferences from commonly-seen task reasoning to specific attribute recognition.
High-resolution aerial images
The images in HRVQA are captured in high resolution (8cm) covering 4 Dutch cities: Amsterdam, Rotterdam, Utrecht, and Enschede.
Language settings
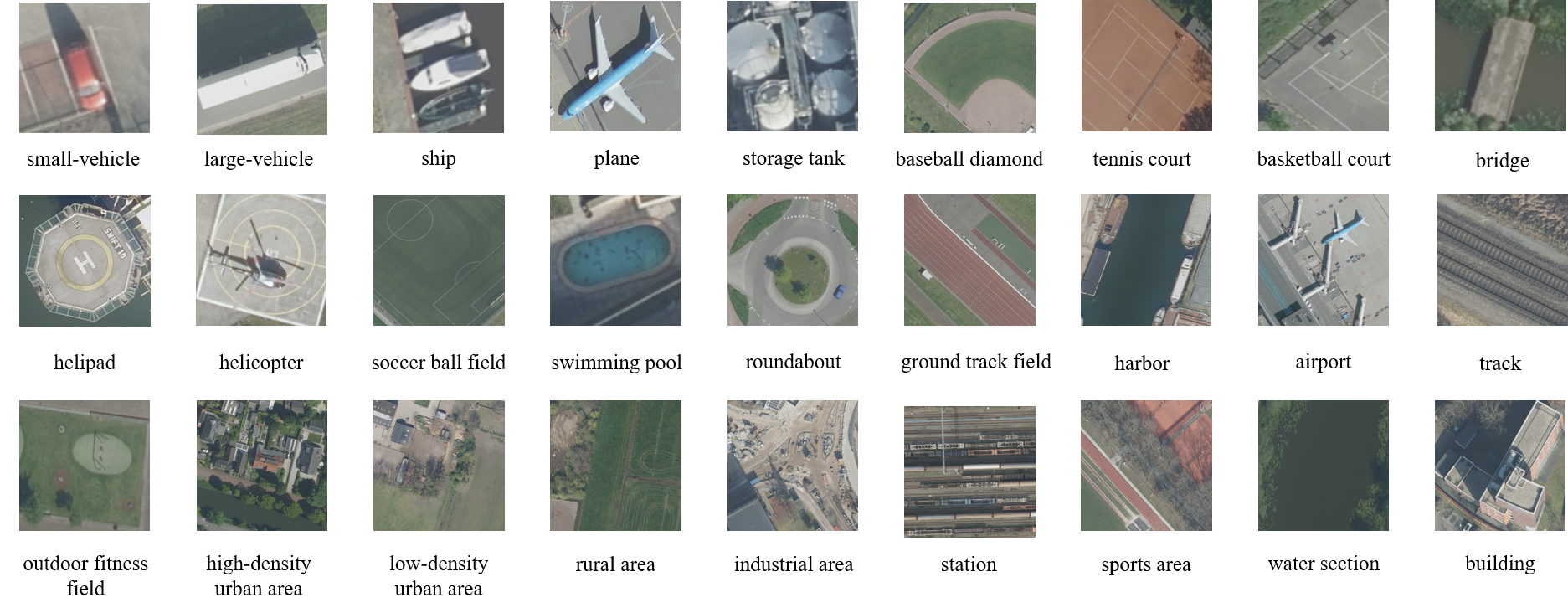
There are 27 category concepts included in HRVQA:
small-vehicle, large-vehicle, ship, plane, storage tank, baseball diamond, tennis court, basketball court, bridge, helipad, helicopter, soccer ball field, swimming pool, roundabout, ground track field, harbor, airport, track, outdoor fitness field, high-density urban area, low-density urban area, rural area, industrial area, station, sports area, water section, and building.The questions are classified into 10 question types based on the aim of the query:
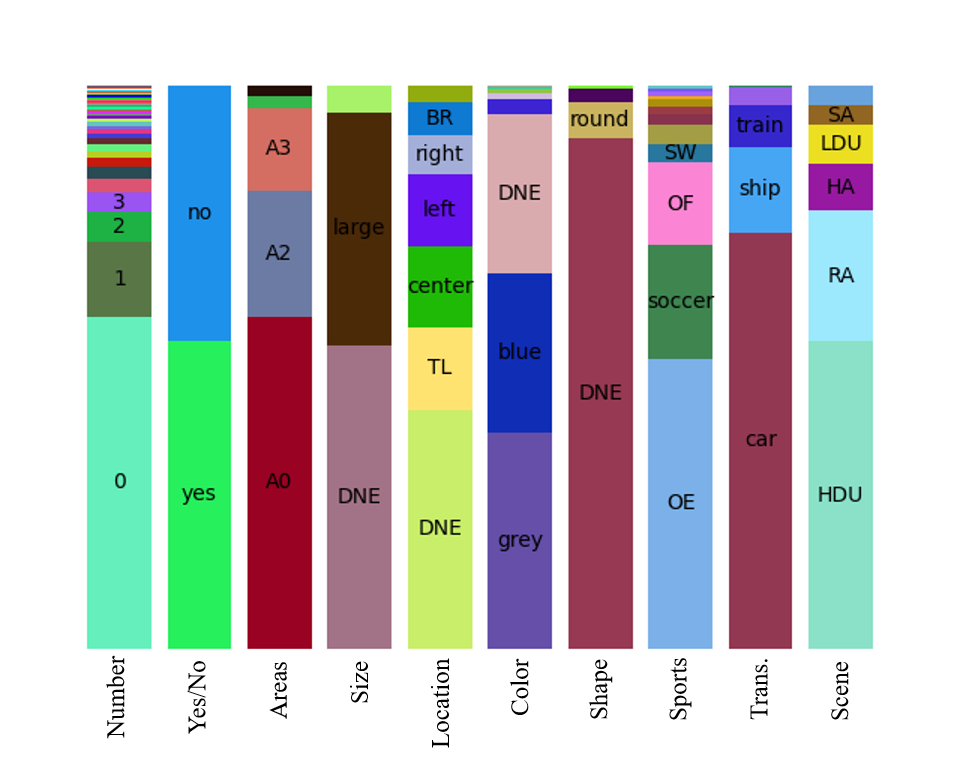
Number, Yes/No, Areas, Size, Location, Color, Shape, Sports, Transportation, and Scene.News
- 22/06/2023.HRVQA v1 is online! HRVQA v1 is released with all images and question/answer annotations for training and validation. Only the image/question pairs are provided for testing.
Copyright
HRVQA dataset is copyright by us and published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 License. This means that you must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license.
Citation
@article{li2023hrvqa,
title={HRVQA: A Visual Question Answering Benchmark for High-Resolution Aerial Images},
author={Li, Kun and Vosselman, George and Yang, Michael Ying},
journal={arXiv preprint arXiv:2301.09460},
year={2023}
}
Privacy and Cookies
Organization

- People
- Contact
 |
 |
 |
Kun Li |
George Vosselman |
Michael Ying Yang |
k.li@utwente.nl
- Image Source
- Ethics Statement
- Download
- Overview
- 27036 aerial images, 540720 question/answer pairs for training
- 6762 aerial images, 135240 question/answer pairs for validation
- 19714 aerial images, 394280 questions for testing
- Question Format
- Answer Format
The high-resolution aerial images in HRVQA are collected from the Open data provided by the Dutch governmental organizations.
As the spatial resolution of the aerial images is very high (8 cm GSD), some personal or commercial information could be further discovered by analyzing the visual context. Note that human face will not be recognizable in such resolution, and other personal details like vehicle plate or house number information will not be detected either. To prevent the abusive usage of HRVQA, anyone who will use the data or method should mark with "research study" and obey the corresponding regulations of dataset usage.
The download link for HRVQA could be found here:
HRVQA consists of three subsets:
The lingual part of this data including questions and annotations follows the same normalization steps (e.g., spelling correction, uppercase and lowercase letters, unified punctuation) on the raw automatically generated data.
The questions are stored using the JSON file format with the following data structure:
{question: [{image_id: int, question: str, question_id: int, image_name: str, question_type: str}, {...}, ...]}
The annotations are stored using the JSON file format with the following data structure:
{Annotations: [{multiple_choice_answer: str, question_id: int}, {...}, ...]}
More python API and evaluation codes for HRVQA project will be released in our github page.
- Some examples of the image/question/answer triplets
The aim for HRVQA dataset is to predict the answer to a question about the content of a given aerial image.
 |
 |
Q: What kind of size is the first outdoor fitness field based on the left to right rule? |
Q: What is the color of the third small vehicle based on the left to right rule in this image? |
A: large scale |
A: blue |
 |
 |
Q: Where is the second storage-tank based on the left to right rule in this image? |
Q: What kind of shape is the roundabout based on the left to right rule in this image? |
A: center |
A: round |
 |
 |
Q: Is there any water sections in this image? |
Q: How many small vehicles can you see in this image? |
A: no |
A: 5 |
 |
 |
Q: What is the main scene of this image? |
Q: Does a building exist in this image? |
A: high-density urban area |
A: yes |
 |
 |
Q: Can you see a green ship in this image? |
Q: What color is the fourth small vehicle based on the left to right rule in this image? |
A: no |
A: grey |
 |
 |
Q: What is the main transportation of this image? |
Q: What kind of scene can you see in this image? |
A: by ship |
A: sports area |
 |
 |
Q: What sport can people do in this image? |
Q: How many small vehicles are visible in this image? |
A: play tennis |
A: 15 |
 |
 |
Q: Which part of this image is the outdoor fitness field located in? |
Q: What is the area covered by tracks in this image? |
A: topright |
A: more than 1000m2 |
- Evaluation
- Benchmark
We provide a evaluation format for HRVQA task.The predictions should be stored using the JSON file format with the following data structure:
[{answer: str, question_id: int}, {...}, ...]
The evaluation server and the benchmark table will be held on Codalab platform.
Here is an example JSON file result before sending to the evaluation server: example for submission.
- Samples of the concepts in HRVQA
- Distribution of answer per question type
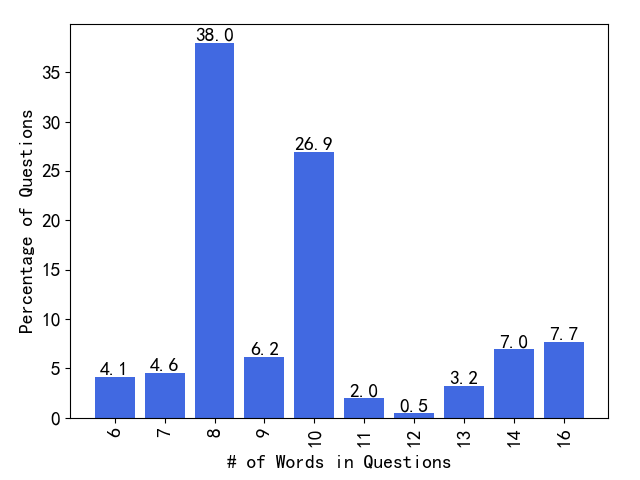
- Distribution of question lengths
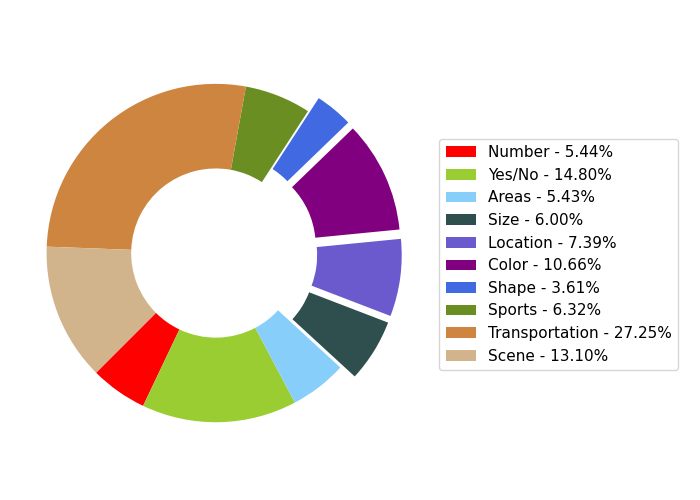
- Distribution of question types